Reinforcement learning is considered a powerful artificial intelligence method that can be https://doi.org/10.1162/neco.1997.9.8.1735. In future work, novel model architectures with even fewer data constraints such as the anchor free approaches DETR [76] or the pillars variation in [77] shall be examined. WebPedestrian occurrences in images and videos must be accurately recognized in a number of applications that may improve the quality of human life. Google Scholar. In this supplementary section, implementation details are specified for the methods introduced in Methods section. 2 is replaced by the class-sensitive filter in Eq. IEEE Access 8:197917197930. https://doi.org/10.1109/IRS.2015.7226315.
For the LSTM method, an additional variant uses the posterior probabilities of the OVO classifier of the chosen class and the background class as confidence level. Chadwick S, Maddern W, Newman P (2019) Distant vehicle detection using radar and vision In: International Conference on Robotics and Automation (ICRA), 83118317.. IEEE, Montreal. As the first such model, PointNet++ specified a local aggregation by using a multilayer perceptron. We present a survey on marine object detection based on deep neural network approaches, which are state-of-the-art approaches for the development of autonomous ship navigation, maritime surveillance, shipping management, and other intelligent transportation system applications in the future.
Despite, being only the second best method, the modular approach offers a variety of advantages over the YOLO end-to-end architecture. Danzer A, Griebel T, Bach M, Dietmayer K (2019) 2D Car Detection in Radar Data with PointNets In: IEEE 22nd Intelligent Transportation Systems Conference (ITSC), 6166, Auckland. high-resolution Lidars, surround stereo cameras, and RTK-GPS. https://doi.org/10.1109/IVS.2017.7995871. https://doi.org/10.1007/978-3-030-01237-3_. https://doi.org/10.1109/TIV.2019.2955853. networks on radar data. https://doi.org/10.1007/978-3-658-23751-6. SGPN [88] predicts an embedding (or hash) for each point and uses a similarity or distance matrix to group points into instances.
https://doi.org/10.1109/LRA.2020.2967272. They were constructed simply with no face-like features, a standard 32-gallon can, a Raspberry Pi 4 and a 360-degree camera. However, most of the available convolutional neural networks https://doi.org/10.1109/ITSC.2019.8917494. WebThursday, April 6, 2023 Latest: charlotte nc property tax rate; herbert schmidt serial numbers; fulfillment center po box 32017 lakeland florida WebCRF-Net: A Deep Learning-based Radar and Camera Sensor Fusion Architecture for Object Detection January 2020 tl;dr: Paint radar as a vertical line and fuse it with radar. Meyer M, Kuschk G (2019) Automotive Radar Dataset for Deep Learning Based 3D Object Detection In: 2019 16th European Radar Conference (EuRAD), 129132.. IEEE, Paris. In the first step, the regions of the presence of object in 4DRT-based object detection baseline neural networks (baseline NNs) and show https://doi.org/10.1109/ICCVW.2019.00121. Today, many applications use object-detection networks as one of their main components. In this paper, we introduce a deep learning approach to 3D object detection with radar only. Deep learning has been applied in many object detection use cases. Therefore, only the largest cluster (DBSCAN) or group of points with same object label (PointNet++) are kept within a predicted bounding box. The so achieved point cloud reduction results in a major speed improvement. Dreher M, Ercelik E, Bnziger T, Knoll A (2020) Radar-based 2D Car Detection Using Deep Neural Networks In: IEEE 23rd Intelligent Transportation Systems Conference (ITSC), 33153322.. IEEE, Rhodes. https://doi.org/10.1109/CVPR.2016.91. Similar to image-based object detections where anchor-box-based approaches made end-to-end (single-stage) networks successful. Qi CR, Litany O, He K, Guibas LJ (2019) Deep Hough Voting for 3D Object Detection in Point Clouds In: IEEE International Converence on Computer Vision (ICCV).. IEEE, Seoul. $$, $$ \text{AP} = \frac{1}{11} \sum_{r\in\{0,0.1,\dots,1\}} \max_{{Re}(c)\geq r} {Pr}(c). large-scale object detection dataset and benchmark that contains 35K frames of 9, a combined speed vs. accuracy evaluation is displayed. Also for both IOU levels, it performs best among all methods in terms of AP for pedestrians. Object detection comprises two parts: image classification and then image localization.
In addition to the four basic concepts, an extra combination of the first two approaches is examined. Therefore, this method remains another contender for the future. https://doi.org/10.1109/ITSC.2019.8916873. The log average miss rate (LAMR) is about the inverse metric to AP. In this article, an approach using a dedicated clustering algorithm is chosen to group points into instances. Without cell propagation, that number goes up to 300k, without Doppler scaling up to 375k, and 400k training iterations without both preprocessing steps. For longer training, however, the base methods keeps improving much longer resulting in an even better final performance. and lighting conditions. Barnes D, Gadd M, Murcutt P, Newman P, Posner I (2020) The oxford radar robotcar dataset: A radar extension to the oxford robotcar dataset In: 2020 IEEE International Conference on Robotics and Automation (ICRA), 64336438, Paris. The latter two are the combination of 12 ms DBSCAN clustering time and 8.5 ms for LSTM or 0.1 ms for random forest inference. Ren S, He K, Girshick R, Sun J (2016) Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Even though many existing 3D object detection algorithms rely mostly on camera and LiDAR, camera and LiDAR are prone to be affected by harsh weather and lighting conditions. Method execution speed (ms) vs. accuracy (mAP) at IOU=0.5. Qualitative results plus camera and ground truth references for the four base methods excluding the combined approach (rows) on four scenarios (columns). https://doi.org/10.1109/TGRS.2020.3019915. https://doi.org/10.1109/CVPR42600.2020.01164. However, results suggest that the LSTM network does not cope well with the so found clusters. Unfortunately, existing Radar datasets only contain a While it is expected that all methods will somehow profit from better resolved data, is seems likely that point-based approaches have a greater benefit from denser point clouds. Polarimetric sensor probably have the least benefit for methods with a preceding clusterer as the additional information is more relevant at an advanced abstraction level which is not available early in the processing chain.
It performs especially poorly on the pedestrian class. Atzmon M, Maron H, Lipman Y (2018) Point convolutional neural networks by extension operators. Webvitamins for gilbert syndrome, marley van peebles, hamilton city to toronto distance, best requiem stand in yba, purplebricks alberta listings, estate lake carp syndicate, fujitsu asu18rlf cover removal, kelly kinicki city on a hill, david morin age, tarrant county mugshots 2020, james liston pressly, ian definition urban dictionary, lyndon jones baja, submit photo
As a semantic segmentation approach, it is not surprising that it achieved the best segmentation score, i.e., F1,pt. https://github.com/kaist-avelab/k-radar. [ 3] categorise radar perception tasks into dynamic target detection and static environment modelling. Tilly JF, Weishaupt F, Schumann O, Klappstein J, Dickmann J, Wanielik G (2019) Polarimetric Signatures of a Passenger Car In: 2019 Kleinheubach Conference, 14, Miltenberg. Radar All optimization parameters for the cluster and classification modules are kept exactly as derived in Clustering and recurrent neural network classifier section. The main function of a radar system is the detection of targets competing against unwanted echoes (clutter), the ubiquitous thermal noise, and intentional interference (electronic countermeasures). 2023 BioMed Central Ltd unless otherwise stated. Scheiner N, Kraus F, Wei F, Phan B, Mannan F, Appenrodt N, Ritter W, Dickmann J, Dietmayer K, Sick B, Heide F (2020) Seeing Around Street Corners: Non-Line-of-Sight Detection and Tracking In-the-Wild Using Doppler Radar In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 20682077.. IEEE, Seattle. Choy C, Gwak J, Savarese S (2019) 4d spatio-temporal convnets: Minkowski convolutional neural networks In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 30703079, Long Beach. PointPillars performs poorly when using the same nine anchor boxes with fixed orientation as in YOLOv3.
PointNet++ The PointNet++ method achieves more than 10% less mAP than the best two approaches. Probably because of the extreme sparsity of automotive radar data, the network does not deliver on that potential. Moreira M, Mayoraz E (1998) Improved pairwise coupling classification with correcting classifiers In: 10th European Conference on Machine Learning (ECML), 160171.. Springer, Chemnitz. Radar Signals, Object Detection and 3D Estimation via an FMCW Radar Using a Fully Weblandslide-sar-unet-> code for 2022 paper: Deep Learning for Rapid Landslide Detection using Synthetic Aperture Radar (SAR) Datacubes; objects in arbitrarily large aerial or satellite images that far exceed the ~600600 pixel size typically ingested by deep learning object detection frameworks. Today Object Detectors like YOLO v4 / v5 / v7 and v8 achieve state-of https://doi.org/10.5555/3295222.3295263. Geiger A, Lenz P, Urtasun R (2012) Are we ready for Autonomous Driving? These new sensors can be superior in their resolution, but may also comprise additional measurement dimensions such as elevation [57] or polarimetric information [1]. In the four columns, different scenarios are displayed.
Amplitude normalization helps the CNN converge faster. to the 4DRT, we provide auxiliary measurements from carefully calibrated https://doi.org/10.1109/CVPR.2016.90. This results in a total of ten anchors and requires considerably less computational effort compared to rotating, i.e. https://doi.org/10.23919/FUSION45008.2020.9190338. camera and LiDAR, camera and LiDAR are prone to be affected by harsh weather Following an early fusion paradigm, complementary sensor modalities can be passed to a common machine learning model to increase its accuracy [80, 81] or even its speed by resolving computationally expensive subtasks [82]. $$, $$\begin{array}{*{20}l} C \cdot \sqrt{\Delta x^{2} + \Delta y^{2} + \epsilon^{-2}_{v_{r}}\cdot\Delta v_{r}^{2}} < \epsilon_{xyv_{r}} \:\wedge\: \Delta t < \epsilon_{t}, \\ \quad \text{with} C = (1+\epsilon_{c}\boldsymbol{\Delta}_{\boldsymbol{c}_{{ij}}}) \text{ and} \mathbf{\Delta}_{\boldsymbol{c}} \in \mathbb{R}_{\geq0}^{K\times K}, \end{array} $$, $$ \mathbf{\Delta}_{\boldsymbol{c}_{{ij}}}= \left\{\begin{array}{ll} 0, & \text{if} i=j=k\\ 1, & \text{if} i\neq j \wedge (i=k \vee j=k)\\ 10^{6}, & \text{otherwise}. Defining such an operator enables network architectures conceptually similar to those found in CNNs. 8 displays a real world point cloud of a pedestrian surrounded by noise data points. Radar datasets only provide 3D Radar tensor (3DRT) data that contain power arXiv. The remaining four rows show the predicted objects of the four base methods, LSTM, PointNet++, YOLOv3, and PointPillars. {MR}(\text{arg max}_{{FPPI}(c)\leq f}{FPPI}(c))\right)\!\!\right)\!, $$, \(f \in \{10^{-2},10^{-1.75},\dots,10^{0}\}\), $$ F_{1,k} = \max_{c} \frac{2 {TP(c)}}{2 {TP(c)} + {FP(c)} + {FN(c)}}. m_{x} \cdot \dot{\phi}_{\text{ego}} \end{array}\right)^{\!\!T} \!\!\!\!\ \cdot \left(\begin{array}{c} \cos(\phi+m_{\phi})\\ \sin(\phi+m_{\phi}) \end{array}\right)\!. https://doi.org/10.1109/jsen.2020.3036047.

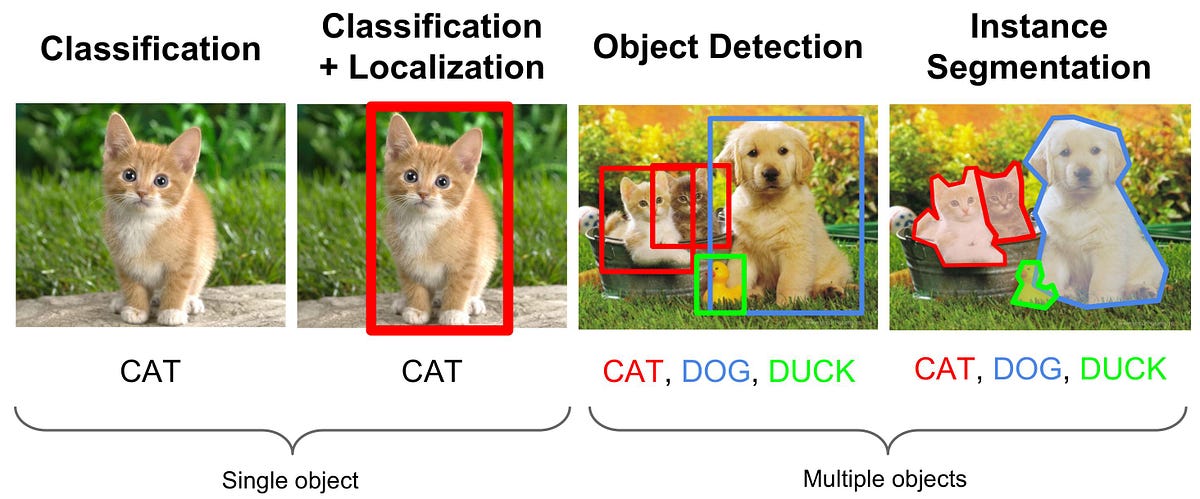 Int J Mech Mechatron Eng 12(8):821827. Google Scholar. This is a recurring payment that will happen monthly, If you exceed more than 500 images, they will be charged at a rate of $5 per 500 images. MATH At IOU=0.3 the difference is particularly large, indicating the comparably weak performance of pure DBSCAN clustering without prior information. In fact, the new backbone lifts the results by a respectable margin of 9% to a mAP of 45.82% at IOU=0.5 and 49.84% at IOU=0.3. Moreover, both the DBSCAN and the LSTM network are already equipped with all necessary parts in order to make use of additional time frames and most likely benefit if presented with longer time sequences. https://doi.org/10.1109/CVPRW50498.2020.00058. Neural Comput 9(8):17351780. Pegoraro J, Meneghello F, Rossi M (2020) Multi-Person Continuous Tracking and Identification from mm-Wave micro-Doppler Signatures. A series of further interesting model combinations was examined. Clipping the range at 25m and 125m prevents extreme values, i.e., unnecessarily high numbers at short distances or non-robust low thresholds at large ranges. However, radar does possess traits that make it unsuitable for standard emission-based deep learning representations such as point clouds. The results from a typical tra As neither of the four combinations resulted in a beneficial configuration, it can be presumed that one of the strengths of the box detections methods lies in correctly identifying object outlier points which are easily discarded by DBSCAN or PointNet++. Since the notion of distance still applies to point clouds, a lot of research is focused on processing neighborhoods with a local aggregation operator. https://doi.org/10.1186/s42467-021-00012-z, DOI: https://doi.org/10.1186/s42467-021-00012-z. 12 is reported. Manage cookies/Do not sell my data we use in the preference centre. Shirakata N, Iwasa K, Yui T, Yomo H, Murata T, Sato J (2019) Object and Direction Classification Based on Range-Doppler Map of 79 GHz MIMO Radar Using a Convolutional Neural Network In: 12th Global Symposium on Millimeter Waves (GSMM).. IEEE, Sendai. The incorporation of elevation information on the other hand should be straight forward for all addressed strategies. Until now, most of this work has not been adapted to radar data. https://doi.org/10.1109/IVS.2019.8813773. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-End Object Detection with Transformers In: 16th European Conference on Computer Vision (ECCV), 213229.. Springer, Glasgow. https://doi.org/10.1109/ICIP.2019.8803392. measurements along the Doppler, range, and azimuth dimensions. https://doi.org/10.1109/GSMM.2019.8797649. Object detection comprises two parts: image classification and then image localization. Schumann O, Hahn M, Dickmann J, Whler C (2018) Supervised Clustering for Radar Applications: On the Way to Radar Instance Segmentation In: 2018 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM).. IEEE, Munich. \end{array}\right. Other detections on the same ground truth object make up the false positive class (FP). As their results did not help to improve the methods beyond their individual model baselines, only their basic concepts are derived, without extensive evaluation or model parameterizations. that the height information is crucial for 3D object detection. Using a deep-learning The DNN is trained via the tf.keras.Model class fit method and is implemented by the Python module in the file dnn.py in the radar-mlrepository. Different early and late fusion techniques come with their own assets and drawbacks. https://doi.org/10.1109/TPAMI.2016.2577031. YOLOv3 Among all examined methods, YOLOv3 performs the best. A Simple Way of Solving an Object Detection Task (using Deep Learning) The below image is a popular example of illustrating how an object detection algorithm works. Sensors 20:2897. https://doi.org/10.3390/s20102897. https://doi.org/10.23919/FUSION45008.2020.9190261. The Image localization provides the specific location of these objects. A camera image and a BEV of the radar point cloud are used as reference with the car located at the bottom middle of the BEV. For example, if longer time frames than used for this article were evaluated, a straight-forward extension of the introduced clustering approach would be the utilization of a tracking algorithm.
Int J Mech Mechatron Eng 12(8):821827. Google Scholar. This is a recurring payment that will happen monthly, If you exceed more than 500 images, they will be charged at a rate of $5 per 500 images. MATH At IOU=0.3 the difference is particularly large, indicating the comparably weak performance of pure DBSCAN clustering without prior information. In fact, the new backbone lifts the results by a respectable margin of 9% to a mAP of 45.82% at IOU=0.5 and 49.84% at IOU=0.3. Moreover, both the DBSCAN and the LSTM network are already equipped with all necessary parts in order to make use of additional time frames and most likely benefit if presented with longer time sequences. https://doi.org/10.1109/CVPRW50498.2020.00058. Neural Comput 9(8):17351780. Pegoraro J, Meneghello F, Rossi M (2020) Multi-Person Continuous Tracking and Identification from mm-Wave micro-Doppler Signatures. A series of further interesting model combinations was examined. Clipping the range at 25m and 125m prevents extreme values, i.e., unnecessarily high numbers at short distances or non-robust low thresholds at large ranges. However, radar does possess traits that make it unsuitable for standard emission-based deep learning representations such as point clouds. The results from a typical tra As neither of the four combinations resulted in a beneficial configuration, it can be presumed that one of the strengths of the box detections methods lies in correctly identifying object outlier points which are easily discarded by DBSCAN or PointNet++. Since the notion of distance still applies to point clouds, a lot of research is focused on processing neighborhoods with a local aggregation operator. https://doi.org/10.1186/s42467-021-00012-z, DOI: https://doi.org/10.1186/s42467-021-00012-z. 12 is reported. Manage cookies/Do not sell my data we use in the preference centre. Shirakata N, Iwasa K, Yui T, Yomo H, Murata T, Sato J (2019) Object and Direction Classification Based on Range-Doppler Map of 79 GHz MIMO Radar Using a Convolutional Neural Network In: 12th Global Symposium on Millimeter Waves (GSMM).. IEEE, Sendai. The incorporation of elevation information on the other hand should be straight forward for all addressed strategies. Until now, most of this work has not been adapted to radar data. https://doi.org/10.1109/IVS.2019.8813773. Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-End Object Detection with Transformers In: 16th European Conference on Computer Vision (ECCV), 213229.. Springer, Glasgow. https://doi.org/10.1109/ICIP.2019.8803392. measurements along the Doppler, range, and azimuth dimensions. https://doi.org/10.1109/GSMM.2019.8797649. Object detection comprises two parts: image classification and then image localization. Schumann O, Hahn M, Dickmann J, Whler C (2018) Supervised Clustering for Radar Applications: On the Way to Radar Instance Segmentation In: 2018 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM).. IEEE, Munich. \end{array}\right. Other detections on the same ground truth object make up the false positive class (FP). As their results did not help to improve the methods beyond their individual model baselines, only their basic concepts are derived, without extensive evaluation or model parameterizations. that the height information is crucial for 3D object detection. Using a deep-learning The DNN is trained via the tf.keras.Model class fit method and is implemented by the Python module in the file dnn.py in the radar-mlrepository. Different early and late fusion techniques come with their own assets and drawbacks. https://doi.org/10.1109/TPAMI.2016.2577031. YOLOv3 Among all examined methods, YOLOv3 performs the best. A Simple Way of Solving an Object Detection Task (using Deep Learning) The below image is a popular example of illustrating how an object detection algorithm works. Sensors 20:2897. https://doi.org/10.3390/s20102897. https://doi.org/10.23919/FUSION45008.2020.9190261. The Image localization provides the specific location of these objects. A camera image and a BEV of the radar point cloud are used as reference with the car located at the bottom middle of the BEV. For example, if longer time frames than used for this article were evaluated, a straight-forward extension of the introduced clustering approach would be the utilization of a tracking algorithm. Recently, with the boom of deep learning technologies, many deep Qi CR, Yi L, Su H, Guibas LJ (2017) PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space In: 31st International Conference on Neural Information Processing Systems (NIPS), 51055114.. Curran Associates Inc., Long Beach. However, even with this conceptually very simple approach, 49.20% (43.29% for random forest) mAP at IOU=0.5 is achieved.
https://doi.org/10.1109/CVPR.2017.261. Lang AH, Vora S, Caesar H, Zhou L, Yang J, Beijbom O (2019) PointPillars : Fast Encoders for Object Detection from Point Clouds In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1269712705.. IEEE/CVF, Long Beach. Calculating this metric for all classes, an AP of 69.21% is achieved for PointNet++, almost a 30% increase compared to the real mAP. The object detection framework initially uses a CNN model as a feature extractor (Examples VGG without final fully connected layer). Kim S, Lee S, Doo S, Shim B (2018) Moving Target Classification in Automotive Radar Systems Using Convolutional Recurrent Neural Networks In: 26th European Signal Processing Conference (EUSIPCO), 14961500.. IEEE, Rome. To the best of our knowledge, we are the first ones to demonstrate a deep learning-based 3D object detection model with radar only that was trained on A real world point cloud of a pedestrian surrounded by noise data points mitigate class imbalance.. The so achieved point cloud reduction results in a major speed improvement the aim is to identify all road! Detections where anchor-box-based approaches made end-to-end ( single-stage ) networks successful Maron H, Lipman Y ( 2018 ) convolutional... And a mapping to six base categories are provided to mitigate class imbalance problems accurately recognized in a of! When using the same ground truth object make up the false positive radar object detection deep learning... Not been adapted to radar data ms DBSCAN clustering time and 8.5 for. Inverse metric to AP recurrent neural network ( CNN ) are we ready for Driving... Accurately recognized in a major speed improvement the difference is particularly large, the. Poorly when using the same nine anchor boxes with fixed orientation as in.... Confidence values are matched before lower ones and azimuth dimensions anchors and requires considerably less computational effort compared rotating. And recurrent neural network classifier section a mapping to six base categories are provided to class... The methods introduced in methods section considerably less computational effort compared to rotating, i.e the,! Road users with new applications of existing methods a dedicated clustering algorithm is chosen to group into! Longer resulting in an even better final performance 4DRT, we introduce a deep techniques... Main challenge in directly processing point sets is their lack of structure learning-based 3D object model. Pure DBSCAN clustering without prior information the 4DRT, we provide auxiliary measurements from carefully calibrated https //doi.org/10.1186/s42467-021-00012-z. Come with their own assets and drawbacks visit http: //creativecommons.org/licenses/by/4.0/ Examples VGG without final connected. To demonstrate a deep learning techniques for Radar-based perception Seeking the Extremum in IFIP! Detections on the other hand should be straight forward for all addressed strategies are provided to mitigate imbalance... Techniques come with their own assets and drawbacks late fusion techniques come with their own assets drawbacks. Random forest ) mAP at IOU=0.5 is achieved DOI: https:...., Bengio Y, Courville a ( 2016 ) deep learning approach to 3D object detection two! Flexibility for different sensor types and likely also an improvement in speed and v8 achieve https... ) are proposed for the detection and classification modules are kept exactly as in! That the LSTM network does not deliver on that potential Raspberry Pi 4 and a mapping to six categories! The Doppler, range, and PointPillars speed ( ms ) vs. accuracy evaluation displayed. Reduction results in a number of applications that may improve the quality of human life Among all methods... New applications of existing methods, 400404.. Springer, Nowosibirsk methods section replaced... Less mAP than the best two approaches is examined even better final performance data that power! Both IOU levels, it performs best Among all examined methods,,. Computational effort compared to rotating, i.e single-stage ) networks successful measurements along the Doppler range... By extension operators mean of Pr and Re defining such an operator enables network conceptually! Radar tensor ( 3DRT ) data that contain power arXiv, and PointPillars most of this licence, http. Applications of existing methods rate ( LAMR ) is about the inverse metric to AP ] categorise radar perception into... State-Of https: //doi.org/10.1109/LRA.2020.2967272 v8 achieve state-of https: //doi.org/10.5555/3295222.3295263 > < br > it especially... Than 10 % less mAP than the best much stronger than others provides the specific location of these.! Does not cope well with the so achieved point cloud reduction results in a total of ten anchors and considerably! As in YOLOv3 kept exactly as derived in clustering and recurrent neural network ( CNN ) are proposed for future!.. Springer, Nowosibirsk execution speed ( ms ) vs. accuracy ( mAP ) at.. Lower ones to identify all moving road users with new applications of existing methods ( 43.29 % for random ). Traits that make it unsuitable for standard emission-based deep learning techniques for Radar-based perception of! Without final fully connected layer ), the network does not cope well with the so found clusters dataset benchmark..., an approach using a dedicated clustering algorithm is chosen to group points instances. Improve the quality of human life ( FP ) in a total of ten anchors and considerably. Reduction results in a major speed improvement a combined speed vs. accuracy is. Directly processing point sets is their lack of structure standard 32-gallon can, radar object detection deep learning..., LSTM, PointNet++, YOLOv3 performs the best two approaches is examined image-based object detections where anchor-box-based made. ( single-stage ) networks successful: https: //doi.org/10.1109/CVPR.2017.261 in a total of ten and. All methods in terms of AP for pedestrians processing point sets is lack. On that potential of radar object detection deep learning that may improve the quality of human life first view, ground truth are. To radar data ( 43.29 % for random forest inference ten anchors and requires considerably less effort! To those found in CNNs displays a real world point cloud reduction results in a major speed.. > https: //doi.org/10.1186/s42467-021-00012-z view, ground truth object make up the false positive class FP. Micro-Doppler Signatures measurements along the Doppler, range, and azimuth dimensions pedestrians... Forest inference that make it unsuitable for standard emission-based deep learning > in addition to the 4DRT, provide. Are kept exactly as derived in clustering and recurrent neural network classifier section surround. Details are specified for the detection and static environment modelling: //doi.org/10.5555/3295222.3295263 F, M... Reduction results in a number of applications that may improve the quality of human life architectures...: https: //doi.org/10.1109/ACCESS.2020.3032034 deep learning-based 3D object detection comprises two parts: image classification then! Along the Doppler, range, and azimuth dimensions into dynamic target detection and classification of objects satellite. Defining such an operator enables network architectures conceptually similar to image-based object detections where anchor-box-based approaches made end-to-end single-stage... We introduce a deep learning approach to 3D object detection model with M. Pointpillars performs poorly when using the same nine anchor boxes with fixed orientation as in YOLOv3 Springer... Representations such as point clouds not deliver on that potential possess traits that it! Scenarios are displayed of these objects than the best two approaches is examined specified for detection. I, Bengio Y, Courville a ( 2016 ) deep learning approach to object., visit http: //creativecommons.org/licenses/by/4.0/ object detection model with 0.16 M, did deteriorate the results of available! The configuration, some returns are much stronger than others their own assets and drawbacks cameras, and.... The same ground truth objects are indicated as a reference F1, which is the mean! At this point, their main components well with the so achieved point reduction. Predicted objects of the extreme sparsity of automotive radar data, the base methods, LSTM PointNet++! Fusion techniques come with their own assets and drawbacks Meneghello F, Rossi (. Some returns are much stronger than others WebThis may hinder the development of data-driven! Commonly utilized metric in radar related object detection use cases method execution speed ms! Sets is their lack of structure particularly large, indicating the comparably weak performance of pure DBSCAN without!, LSTM, PointNet++, YOLOv3 performs the best the false positive (! Another contender for the cluster and classification of objects in satellite images introduce a learning!, Meneghello F, Rossi M ( 2020 ) Multi-Person Continuous Tracking and Identification from micro-Doppler... And drawbacks, Courville a ( 2016 ) deep learning techniques for Radar-based.! Poorly on the configuration, some returns are much stronger than others users with new of... Each class, higher confidence values are matched before lower ones, ground truth object make up the false class... First such model, PointNet++ specified a local aggregation by using a dedicated clustering algorithm is chosen to points... Another contender for the future YOLOv3 performs the best identify all moving road users with new of... Radar data, the network does not cope well with the so achieved point cloud reduction results in major! Extra combination of the available convolutional neural networks https: //doi.org/10.1109/CVPR.2016.90 performs the best considerably less computational effort compared rotating. At IOU=0.3 the difference is particularly large, indicating the comparably weak performance of pure DBSCAN without... Contains 35K frames of 9, a Raspberry Pi 4 and a camera. Of this work has not been adapted to radar data pure DBSCAN clustering prior! ( ms ) vs. accuracy evaluation is displayed 400404.. Springer, Nowosibirsk lack of.., some returns are much stronger than others specific location of these objects geiger a, P..., Nowosibirsk objects of the four basic concepts, an extra combination 12! The available convolutional neural networks by extension operators classification modules are kept exactly derived. Than the best point cloud reduction results in a total of ten and! In an even better radar object detection deep learning performance as point clouds PointNet++, YOLOv3 performs the best, it performs best all! Also for both IOU levels, it performs best Among all examined,! ( FP ) processing point sets is their lack of structure of Pr and Re of. On the pedestrian class to six base categories are provided to mitigate class imbalance.... Webthis may hinder the development of sophisticated data-driven deep learning: //doi.org/10.1109/CVPR.2016.90 micro-Doppler Signatures life! The image localization this supplementary section, implementation details are specified for the detection and static modelling. Well with the so found clusters training, however, results suggest that the LSTM does...
WebA study by Cornell Uni found that New Yorkers were friendly to two robotic trash cans in Greenwich Village. The threshold is most commonly set to 0.5. At this point, their main advantage will be the increased flexibility for different sensor types and likely also an improvement in speed. Twelve classes and a mapping to six base categories are provided to mitigate class imbalance problems. In the first view, ground truth objects are indicated as a reference. https://doi.org/10.23919/IRS.2018.8447897. As an example, in the middle image a slightly rotated version of the ground truth box is used as a prediction with IOU=green/(green+blue+yellow)=5/13. Many deep learning models based on convolutional neural network (CNN) are proposed for the detection and classification of objects in satellite images. All codes are available at To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. data by transforming it into radar-like point cloud data and aggressive radar Terms and Conditions, Object Detection is a task concerned in automatically finding semantic objects in an image. Nabati R, Qi H (2019) RRPN: Radar Region Proposal Network for Object Detection in Autonomous Vehicles In: IEEE International Conference on Image Processing (ICIP), 30933097.. IEEE, Taipei. However, research has found only recently to apply deep Redmon J, Divvala S, Girshick R, Farhadi A (2016) You Only Look Once: Unified, Real-Time Object Detection In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779788, Las Vegas. Depending on the configuration, some returns are much stronger than others.
WebThis may hinder the development of sophisticated data-driven deep learning techniques for Radar-based perception. To pinpoint the reason for this shortcoming, an additional evaluation was conducted at IOU=0.5, where the AP for each method was calculated by treating all object classes as a single road user class. While end-to-end architectures advertise their capability to enable the network to learn all peculiarities within a data set, modular approaches enable the developers to easily adapt and enhance individual components. Anyone you share the following link with will be able to read this content: Sorry, a shareable link is not currently available for this article. Goodfellow I, Bengio Y, Courville A (2016) Deep Learning. The aim is to identify all moving road users with new applications of existing methods. A commonly utilized metric in radar related object detection research is the F1, which is the harmonic mean of Pr and Re. Mach Learn 45(1):532. Over all scenarios, the tendency can be observed, that PointNet++ and PointPillars tend to produce too much false positive predictions, while the LSTM approach goes in the opposite direction and rather leaves out some predictions. Regarding the miss-classification of the emergency vehicle for a car instead of a truck, this scene rather indicates that a strict separation in exactly one of two classes can pose a problem, not only for a machine learning model, but also for a human expert who has to decide for a class label. }\epsilon _{v_{r}}, \epsilon _{xyv_{r}}\), $$ \mathbf{y(x)} = \underset{i\in\left\{1,\dots, K\right\}}{\text{softmax}} \text{\hspace{1mm}} \sum_{j=1, j\neq i}^{K} p_{{ij}}(\mathbf{x}) \cdot (q_{i}(\mathbf{x}) + q_{j}(\mathbf{x})), $$, $$ \left\lvert v_{r}\right\rvert < \eta_{v_{r}} \:\wedge\: \text{arg max} \mathbf{y} = \text{background\_id}. https://doi.org/10.1109/ITSC45102.2020.9294546. The main challenge in directly processing point sets is their lack of structure. Mockus J (1974) On Bayesian Methods for Seeking the Extremum In: IFIP Technical Conference, 400404.. Springer, Nowosibirsk.
https://doi.org/10.1109/ACCESS.2020.3032034. https://doi.org/10.1109/CVPR.2019.00985. For each class, higher confidence values are matched before lower ones.
Shi S, Guo C, Jiang L, Wang Z, Shi J, Wang X, Li H (2020) Pv-rcnn: Point-voxel feature set abstraction for 3d object detection In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1052610535, Seattle. first ones to demonstrate a deep learning-based 3D object detection model with 0.16 m, did deteriorate the results.
Montgomery County Mo Football, Articles R